머신러닝 교과서 파이토치 편

머신러닝을 처음부터 끝까지 제대로 배워보고 싶다는 생각이 들었다.
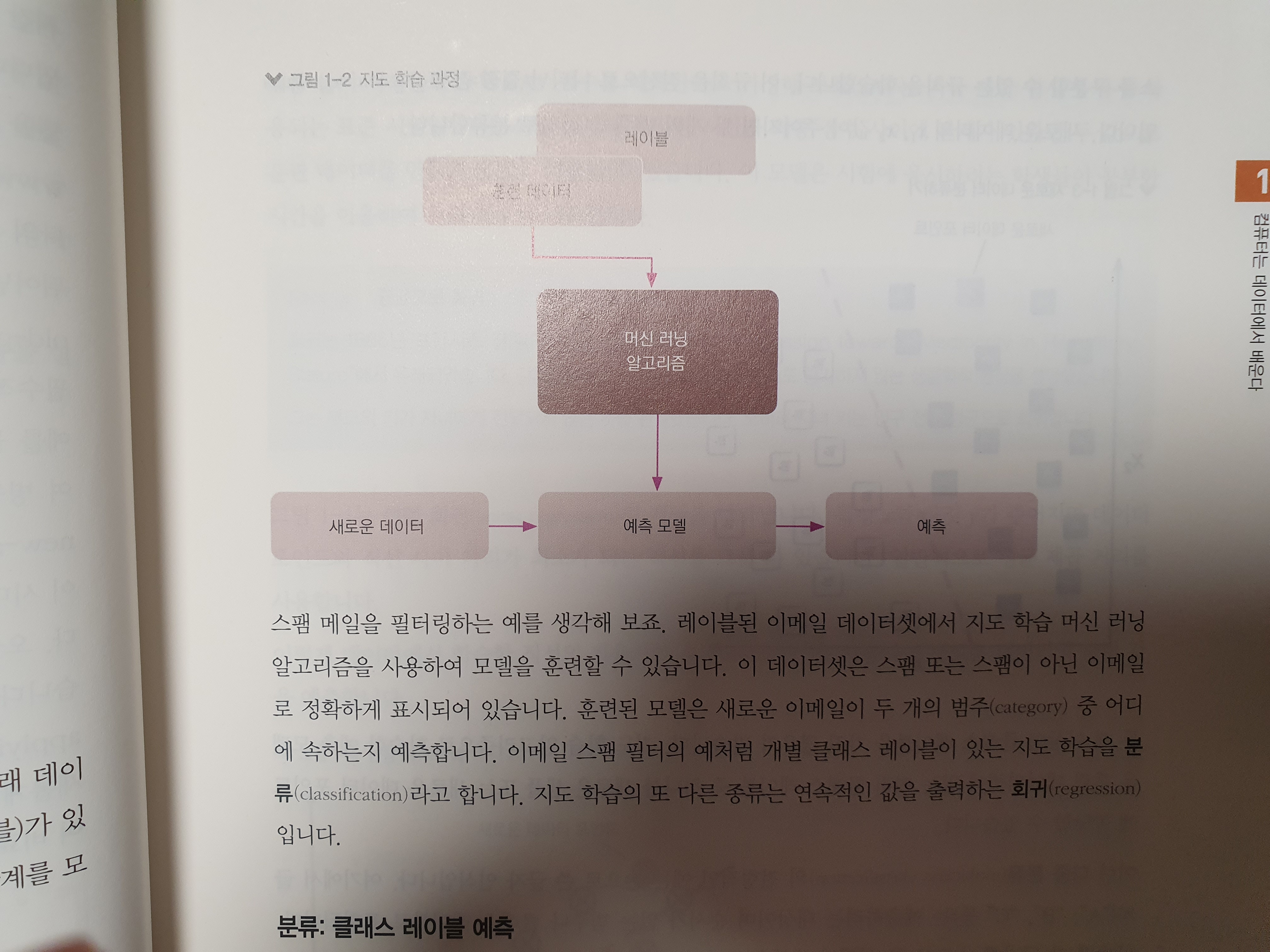
딥러닝과 머신러닝에 대해 들어본 적은 있지만, 얕게 알고 있기 때문에 통계 용어를 정확하게 사용하려면 머신러닝에 대한 지식들을 더 쌓아야 할 필요성을 느꼈다. 특히, 머신러닝이 어떤 학습과정을 거치는지 궁금한 점이 있었는데, 이 책 한권을 공부한다면 빠르게 해결이 가능할 것 같다는 생각이 들었다. 책에서 설명하는 내용에 따르면 머신러닝은 3가지로 나눠지는데, 지도학습, 강화학습, 비지도 학습이 있다. 그 중에서 지도학습은 레이블된 훈련 데이터에서 모델을 학습해 본 적 없는 미래 데이터에 대해 예측을 만드는 것이다. 지도학습의 종류에는 분류, 회귀 등이 있고, 강화학습은 환경과 상호 작용하여 시스템 성능을 향상하는 것이 목적으로, 예를 들어 체스 게임을 들 수 있다. 마지막으로, 비지도 학습은 레이블 되지 않거나 구조를 알 수 없는 데이터를 다루는데, 이것의 종류로는 군집, 차원 축소 등이 있다.
파이썬으로 붗꽃 데이터를 이용하여 퍼셉트론 학습 알고리즘을 구현하는데, 퍼셉트론이 학습한 결정경계가 두 개의 붓꽃으로 구성된 데이터셋의 모든 샘플을 완벽하게 분류한다는 것이 붉은색과 파란색으로 확연하게 드러났다.
또한, 누락된 데이터가 포함된 데이터를 다루는 방법에 대해서 배울 수 있었는데, 열을 완전히 삭제하는 방법도 있지만 중요한 정보를 잃을 위험이 크기 때문에 사용할 때 조심해야 한다. 누락된 값을 대체하는 방법도 있는데, 빈값을 평균으로 대체하는 것이다. 여기서는 사이킷런 추정기를 사용하여 데이터를 변환하는 과정을 보여주었다.
범주형 데이터를 인코딩할 때는 순서가 있는 특성을 매핑하거나, 클래스 레이블을 인코딩하는 방법을 사용한다. 이 또한 사이킷런에 구현된 LabelEncoder 클래스를 사용하면 편리하다.
여러개의 모델과 분류 알고리즘을 연결하는 앙상블 방법에 대해서 잘 설명이 되어있었다. 앙상블의 작동 원리에 대해서 궁금했는데, 다수결 투표를 통해 최빈값을 가지는 클래스 레이블을 선택하면 되는 방식이다. 훈련 데이터셋을 사용하여 m개의 다른 분류기를 훈련시키고, 앙상블 방법에 따라 결정 트리, 서포트 벡터 머신, 로지스틱 회귀 분류기와 같이 다양한 알고리즘을 사용하여 구축할 수 있었다.
이 책의 8장에 해당하는 부분이 감성 분석에 머신러닝을 적용하는 것이다. 개인적으로 가장 궁금했던 내용이어서 따라하면서 매우 재미있었다. 텍스트 처리용 IMDb 영화 리뷰 데이터를 통해, BoW 모델을 기반으로 영화 리뷰를 긍정과 부정 리뷰로 분류하는 로지스틱 회귀 모델을 훈련시켰다. 특히, 머신 러닝 모델이 영화리뷰가 긍정인지 부정인지에 대해서 높은 정확도로 예측하지만, 사용하는 메모리 용량이 많다는 한계가 있다는 점이 흥미있었다. 이를 해결하기 위해 데이터셋을 작은 배치로 나누어 분류기를 점진적으로 학습시킨다고 한다.
마지막장에서 강화학습모델에 대한 설명은 수학적 이해를 필요로 했다. 그러나 강화학습 알고리즘을 구현하는 과정은 재미있었다. OpenAI 짐 툴킷을 사용하여, 막대의 균형을 잡고, 자동차를 산위로 이동시키는 문제였는데 시간이 흐름에 따라서 보상을 증가시키기 위해 학습이 이루어졌고, 30번째 에포크 이후 막대 균형을 잡는데 성공했다는 것을 보고 복잡한 강화학습의 알고리즘에 대해서 이해할 수 있었다.
머신러닝에 입문하는 사람이라면 모두 한번쯤 다뤄보았을 데이터에 대한 다양한 접근을 통해 독자가 이해하기 쉽도록 만들어 준다. 알고리즘 지식이 부족하거나, 머신러닝에 대해서 알고 싶다면 이 책이 기본기를 다지는데 정말 큰 도움이 될 것이다. 이 책을 기본으로 잡고, 응용하여 프로젝트에 활용한다면 도움이 될 것이다.
이 리뷰는 길벗 출판사에서 진행한 서평 이벤트를 통해 도서를 제공받아 작성되었습니다.